
Scrapy框架
Scrapy是一个高效的爬虫框架,方便我们进行爬虫的开发。
Scrapy架构图(绿线是数据流向): 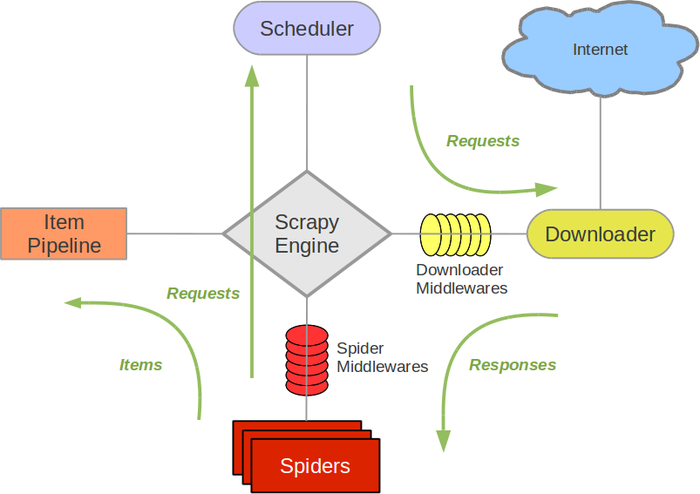
1.升级pip
pip install --upgrade pip
注意:
在命令行升级后输入pip -V查看版本的时候如果提示如下(无法打开): Cannot open E:\python\PycharmProjects\untitled\venv\Scripts\pip-script.py
解决办法:
此问题是只升级了python3下的pip版本,项目下的venv中pip并没有升级,所以出现这样问题的解决办法是复制c:\python3\Scripts下的exe文件到项目venv下的scripts中覆盖并替换旧版本pip。
2.安装Scrapy
pip install Scrapy
3.新建Scrapy项目
scrapy startproject 项目名
例:
scrapy startproject benzhu
问题:
当在pycharm项目出现import scrapy报错的时候。
解决办法:
File >> settings >> Project Interpreter >> +号 >> 搜索scrapy >> 点击Install Package选择和下载的版本一致就行。
4.制作爬虫
4.1创建爬虫
进入mySpider/spider目录 输入如下命令:
scrapy genspider itcast "爬虫名称"
4.2创建模型
打开项目底下的items.py然后在文件中构建一个item模型。
说明一下这个模型类似于Bean,用来构建我们爬虫的对象。
class VirmachItem(scrapy.Item):
price = scrapy.Field()
addres = scrapy.Field()4.3制作爬虫
打开 mySpider/spider目录里的 itcast.py
修改代码制作爬虫,一般需要xpath进行锁定标签对。
response.xpath('xpath语句').
4.4运行爬虫
scrapy crawl 项目名称
4.5.保存数据
scrapy保存信息的最简单的方法主要有四种,-o 输出指定格式的文件,命令如下:
scrapy crawl itcast -o teachers.json
json lines格式,默认为Unicode编码:
scrapy crawl itcast -o teachers.jsonl
csv 逗号表达式,可用Excel打开:
scrapy crawl itcast -o teachers.csv
xml格式:
scrapy crawl itcast -o teachers.xml
4.6.注意
注意: Python2.x默认编码环境是ASCII,当和取回的数据编码格式不一致时,可能会造成乱码;我们可以指定保存内容的编码格式,一般情况下,我们可以在代码最上方添加:
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
评论